Algorithme de moteurs de recherche : comment ça marche ?

Qui n’a jamais entendu un CM dire : « L’algorithme d’Instagram vient de changer, il est beaucoup moins pratique !” ? Et qu’en est-il des autres réseaux sociaux ? Et pour aller plus loin, des algorithmes de moteurs de recherche ?
Lorsque le terme d’algorithme est abordé, il est vite possible d’attraper un énorme mal de crâne, nous vous l’accordons. Suite infinie et logique, ou encore illogique, un algorithme permet certes de résoudre des problèmes rencontrés, mais sa complexité l’amène à devenir l’ennemi du commun des mortels.
Et surtout, suuurtout, c’est un terme restant très compliqué à comprendre…
Mais pas de panique ! Amiltone est là pour vous accompagner, et aller pas à pas vers la compréhension de ce sujet complexe.
Pour la petite histoire, le terme “algorithme” vient du nom du mathématicien persan Al-Khwarizmi, célèbre au IXe siècle. Le mot en lui-même a été emprunté au nom de son ouvrage le plus célèbre “Al-jabr wa-al-muqabilah”, signifiant “réduction et compensation” en arabe. Qui dit mieux ?
Un moteur de recherche, qu’est-ce que c’est ?
Reprenons par la base des bases de l’algorithme
Un moteur de recherche, c’est un moyen de trouver des documents à l’aide de termes et de mots-clés, tout simplement.
Il existe différents types de recherche, que nous développerons au fur et à mesure de cet article :
String
Pattern
Plein texte
Sémantique
String
Par exemple, pour la recherche string, prenez la requête « oranges sanguines”.
Le problème est que si l’utilisateur fait une erreur dans sa barre de recherche, comme mettre une majuscule, mettre la requête au pluriel, ou autre, il ne trouvera pas le résultat qu’il souhaite.
Pattern
C’est pourquoi le pattern est utilisé, bien que compliqué à configurer. Le but est de structurer le code de manière cohérente pour faciliter la résolution de problèmes courants.
Plein texte
Vient alors la recherche plein texte, utilisée par la plupart des moteurs de recherche. Le but étant d’analyser un amas de documents et de trouver tous les termes recherchés. Dans le cas présent, “orange” et “sanguine”.
Sémantique
Il y a également la recherche sémantique, qui, elle, va essayer de trouver le sens de la requête utilisateur. C’est-à-dire qui va essayer de comprendre ce qu’il demande, au lieu de faire une recherche dite “banale” sur les termes.
Par exemple, dans la requête : “Quelle recette cajun avec des oranges sanguines met moins de 30 min à être préparée ?”, la recherche sémantique retiendra “cajun oranges sanguines moins 30 min”.
Les moteurs de recherche retiennent alors les termes les plus importants, et essaient de les catégoriser, comme par exemple le style de cuisine, le type d’ingrédients, la durée…
Tout s’emboîte comme sur des roulettes grâce à l’algorithme !
Pour ce qui est des bases de l’algorithme de moteurs de recherches, nous retrouverons facilement les traitements de requêtes, le crawling et la recherche.
Traitements de requêtes : un traitement de requête est une étape dans la demande d’un utilisateur ou d’un système. Cela peut inclure des actions comme la vérification des données de la requête pour s’assurer que celles-ci sont valides, la recherche d’informations pertinentes, la préparation de la réponse et sa transmission.
Crawling : d’après le JDN, un crawler (qu’il est possible de retrouver sous le nom de “spider”, ou encore de “robot de crawl”) désigne, dans le monde de l’informatique, un robot d’indexation. Sans fioriture : un logiciel qui explorera l’intégralité du Web afin d’analyser son contenu, et le stockera de manière organisée dans un index.
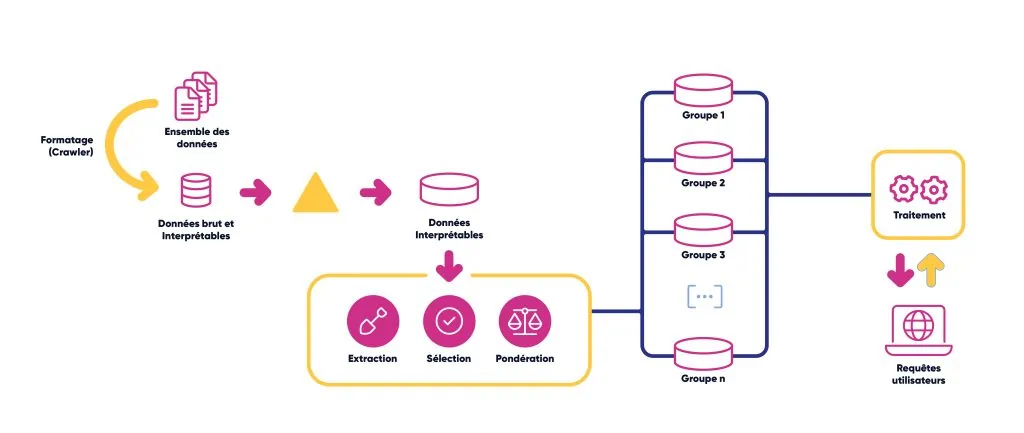
Vue d’ensemble d’un moteur de recherche
Une recherche de base se construit sur plusieurs blocs, et tout s’enchaîne parfaitement et de façon efficace.
Premièrement : le crawling, défini plus haut. Le principe ? C’est très simple ! Avoir l’ensemble des données recherchées, aller chercher cette donnée pour avoir le plus d’informations possibles, le plus de documents que le crawler pourra récupérer, et que celui-ci sait interpréter.
À quoi bon récupérer toutes ces données brutes et ininterprétables me direz-vous ?
Eh bien pour les trier, les réduire, et ne garder que celles étant interprétables et intéressantes. Et ce, afin de pouvoir faire la recherche de base sans qu’il n’y ait d’erreurs, et que l’indexation énoncée plus haut ne soit trop trop longue.
Cette fameuse indexation consiste à prendre toutes les données étant interprétables, et en faire une extraction, une sélection et une pondération. Ensuite, il ne reste plus qu’à les mettre dans différents groupes.
Après quoi, notre recherche utilisateur, qui elle aussi contient une interprétation, une sélection, une transcription et un découpage, va faire des allers-retours avec l’index. Cela va permettre de trouver les résultats demandés selon les termes entrés.
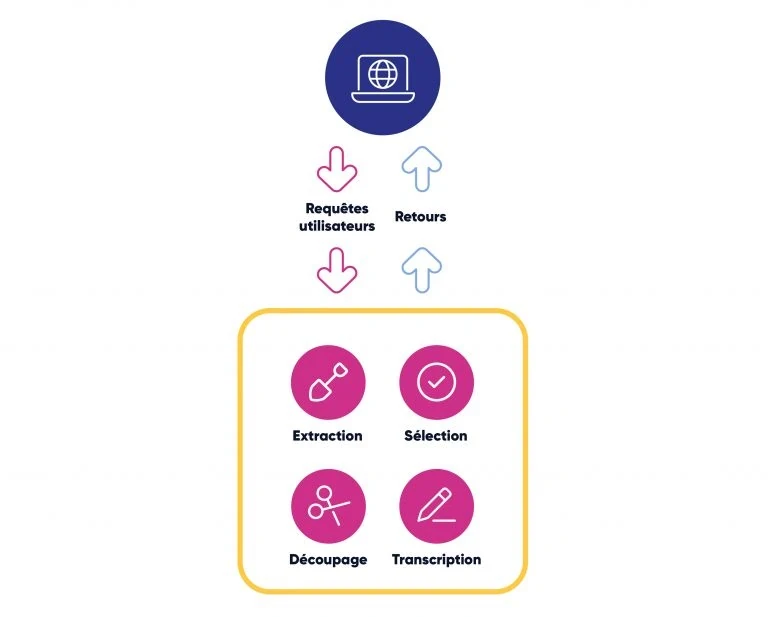
Il est temps de faire une mini-conclusion de ce qui a été vu pour le moment !
Le crawler parcourt les sources et récupère les données en brut
L’indexation va récupérer ces données et les découper en petits groupes
Ces petits groupes vont avoir une adresse, appelée index.
Nous avons également le traitement de la requête qui interprète l’ensemble de la demande utilisateur dans un format comparable à un index.
Enfin, la recherche parcourant les index retourne une liste de documents à l’interface utilisateur.
L’importance de la famille
Il existe 3 grandes familles de moteurs de recherche, Web, entreprise, et applicatif :
Web : celle employée tous les jours par le plus grand nombre d’utilisateurs : utilisée pour chercher une très grande quantité d’informations.
Entreprise : elle concerne les recherches d’une entreprise, comme pour des projets professionnels. Ces moteurs de recherche sont généralement plus puissants que ceux dits « standards ». Ils peuvent également être utilisés pour rechercher des informations à l’intérieur d’un intranet ou d’un réseau privé d’une entreprise.
Applicatif : conçu pour indexer et rechercher des informations à l’intérieur d’une application ou d’un système spécifique. Il est conditionné pour fonctionner dans un environnement fermé, et rechercher des données spécifiques dans une application.
Indexation : on met les mains dans le cambouis
Allons maintenant voir plus en détails l’indexation inverse, le Data Mining, le ranking et le filtering. Certes, ces termes, non expliqués, peuvent sembler n’avoir aucun sens. Mais pour un bon algorithme dans la joie et la bonne humeur, c’est parti !
Entre pouce et index d’un algorithme
Tout d’abord : l’indexation inverse. Nous avons vu ensemble que l’indexation regroupe des documents, et que ces documents sont composés de thèmes.
L’indexation inverse fait gagner un temps considérable à l’utilisateur, et au moteur de recherche. Les pages arrivent alors par ordre décroissant, et par ordre de pertinence.
Cela s’explique grâce à cette logique : chaque mot dispose d’un numéro, et les numéros correspondent à des positions dans des documents d’origine. C’est pourquoi cette structure de données permet d’aller à vitesse grand V, plutôt que de devoir parcourir le document entier pour trouver les mots recherchés.
C’est seulement lorsque la recherche de l’utilisateur se fait plus longue, et sur des termes plus rares, que l’index inversé doit se concentrer sur tous les index concernant les termes composés. Ensuite, il les confronte entre eux pour trouver tous les documents dans lesquels les mots recherchés sont présents.
Data, data, data…
Le Data Mining (ou fouille de données en français), n’est pas inhérent à tous les moteurs de recherche. Chacun l’implémente alors là où il le souhaite. Cependant, la plupart du temps, il se retrouve dans l’indexeur.
Et pour donner une définition exacte, car il n’y a que ça de vrai : “Le Data Mining désigne l’analyse de données depuis différentes perspectives et transforme ces données en informations utiles {…}.” (https://www.oracle.com/fr/database/data-mining-definition.html)
Et qui dit Data Mining, dit six grands principes : Pattern recognition, Tokenization, Lemmatizing, Stopword, Text normalization et le Stemming.
Tout d’abord, le Pattern recognition. C’est ce qui va se trouver dans les moteurs de recherche, et qui va s’occuper d’élaguer tout ce qui n’intéresse pas. C’est-à-dire les balises HTML, tout ce qui se trouve dans les menus mais qui n’est pas utile… Et ainsi de suite !
Pour la Tokenization, nous allons aborder un peu de vocabulaire. Oui, c’en était également jusqu’ici, mais c’est toujours bien de le préciser ! Car tout ceci fait écho à ce que nous appelons dans le jargon : du “traitement naturel de langage”.
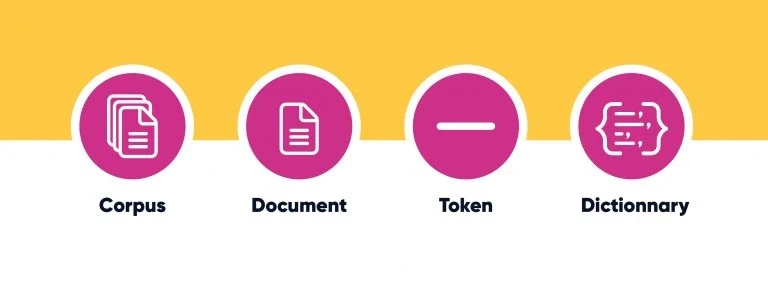
Corpus : Ensemble de documents
Document : Document (ça va ?)
Token : Donnée lexicale extraite d’un document, c’est-à-dire unité d’information de taille variable, mais assimilable et traitable par un ordinateur. Une fois que tout un ensemble de tokens est réuni, il est possible de créer un dictionnaire, qui se retrouvera dans l’index.
Comme expliqué, un token peut embarquer avec lui plusieurs metadata, comme sa place dans le texte, le nombre de fois où il apparaît dans le texte, ou encore dans tout l’ensemble du corpus.
Et c’est à ce moment que l’index, ce fameux index, intervient. Il va le traiter avec des chiffres. Car pour un humain par exemple, lire le mot “œuf” est très simple, mais pour un ordinateur, c’est une tout autre chose.
Un problème subsiste : les majuscules et minuscules. Vous pouvez alors découper votre texte soit en phrase et les indexer, ou découper chaque mot.
C’est à ce moment que le problème des majuscules et minuscules intervient : elles vont faire des entrées dupliquées dans le dictionnaire.
Entrée dupliquée : Le moteur de recherche pourrait alors croire qu’un même élément a été entré plusieurs fois dans la même requête. Votre recherche peut alors se montrer quelque peu défaillante.
C’est pour cela qu’il existe différentes stratégies à adopter pour éviter les mots inutiles dans le dictionnaire ! Eh oui, nous ne vous laissons pas seuls…
Nous retrouvons en première place, le premier algorithme principalement utilisé. Roulement de tambour… Stopword !
C’est un dictionnaire de mots dont nous ne voulons pas. Ils sont extrêmement récurrents, mais ne représentent pas une donnée. Par exemple, il est possible d’y retrouver tous les “et”, “de”…
En deuxième position, la Text normalization. C’est-à-dire que tout passe au même format. Peu importe la langue (japonais, russe, français…), tout disparaît. “Donnée” devient “donnee”, “Œufs” devient “oeufs”. Accents, majuscules… C’est comme les soldes : tout doit disparaître.

Passons à deux concepts un peu particuliers : le Stemming et le Lemmatizing.
En ce qui concerne le Stemming, cet algorithme va chercher à trouver les racines communes lexicalement.
C’est-à-dire que, entre autres, pour les mots “feuillages”, et “feuilles », vous allez retrouver la racine commune qui est les deux -L. Cela permet de simplifier le traitement de données textuelles, et d’améliorer les performances de certains autres algorithmes.
Ainsi, vous ne tomberez pas sur le mot “feuil”, qui ne veut pas du tout dire la même chose, lorsque vous chercherez comment vous débarrasser de vos feuilles mortes !
Le Lemmatizing quant à lui, essaie de légèrement comprendre le sens que vous voulez donner. Pour “beurrage” et “beurré” dans le cadre d’une recette, il est question de l’aliment. La racine commune est bien le beurre, et on ne parle donc pas de quelqu’un d’ivre.
Mais tout ça, il faut bien évidemment le programmer, et le configurer.
Et pour ça, il existe les N-GRAM : c’est faire des petits paquets avec vos données textuelles. L’utilité ? Pouvoir prédire la prochaine séquence de mots dans un texte, en calculant la probabilité du prochain mot. {Comme;ça} {par;exemple;.}
Enfin, si vous mettez tous ces algorithmes à la suite, vous avez votre dictionnaire final !
Stopord → Text normalization → N-GRAM → Tokenization.
A,B,C,Dictionnaire des algorithmes de moteurs de recherche
Une fois ce dictionnaire finalisé, il est nécessaire de lui donner une importance. Pour ce faire, il existe deux algorithmes.
Tout d’abord, le Ranking TF/IDF. Cet algorithme de moteurs de recherche est utilisé pour calculer la pertinence d’un mot dans un document, par rapport à une collection de documents. TF mesure le nombre de fois où un terme apparaît dans un document, lorsque la fréquence inverse, IDF, mesure l’importance d’un terme. Et ce, en prenant en compte sa fréquence dans l’ensemble du corpus.
N.B. : Plus un terme est fréquent dans un document, mais rare dans tout le corpus, plus il sera considéré comme important pour ce document en particulier.
Dans un second temps nous retrouverons le Ranking BM-25. Voisin du TF/IDF, il ne calculera pas la pertinence d’un mot mais d’un document selon plusieurs facteurs. Par exemple, la fréquence des termes dans le document, ou encore la longueur de celui-ci.
Cette partie-là se trouvant entre la recherche utilisateur et le Filtering, voyons ensemble ce dernier !
Le Filtering consiste à classer vos résultats de recherche remontés par le ranking suivant certains critères spécifiques, comme en différentes catégories.
Ce classement va être distingué en deux types. Principalement, il est possible de retrouver la classification énumérative. C’est un arbre où ces catégories sont subdivisées au fur et à mesure.
Par exemple, imaginez une recette telle un arbre généalogique, où les ingrédients sont de plus en plus précis et divisés.
Sauf que cet arbre a un gros inconvénient, c’est qu’il est difficile de tout catégoriser à l’intérieur. Il y a des éléments qui vont être à cheval entre deux catégories et le parcours est en général assez fastidieux. Imaginez que votre cousin est votre père et votre fils en même temps, il faut revenir en arrière pour remonter les générations, ça perd du sens… Attention spoiler : vous êtes un peu dans Dark, si vous avez la ref.

C’est pourquoi les chercheurs ont inventé un autre système de classification appelé la Faceted classification. Dans ce système, il est toujours question de classer les catégories, mais cette fois, sans les hiérarchiser entre elles. Il est alors possible de les parcourir comme bon vous semble.
Être interprété, ou ne pas être interprété, telle est la question
Il est ici question de Data Mining. Et ce qui est principalement recherché, et qui va aider à faire de la recherche sémantique, c’est nommer les entités trouvées.
Par exemple, pour une recette de cuisine :
Cajun : style de cuisine
Oranges sanguines : ingrédients
30 min : une durée
Pour ce faire, il existe deux composants à utiliser. Tout d’abord, l’Index thesauri. Il correspond à un dictionnaire de synonymes, mais en beaucoup plus compliqué. C’est-à-dire que celui-ci va faire des liens de hiérarchies entre les mots, mais aussi entre les synonymes.
Par exemple, pour orange, le terme plus générique pour qualifier ce mot est agrume. Moins générique cette fois, orange sanguine. Un terme relatif : clémentine ou mandarine.
Il est également possible de faire une hiérarchie entre un langage courant que des utilisateurs vont pouvoir utiliser, ou un langage professionnel. C’est ainsi que patate devient pomme de terre (jusqu’ici tout va bien) ou que téléphone portable devient téléphone cellulaire si vous travaillez dans la téléphonie.
En conclusion, tout cela permet de faire une map des synonymes, que le moteur de recherche va pouvoir parcourir pour essayer de trouver le sens et la catégorie à laquelle appartient votre requête.
Le deuxième composant que nous pouvons retrouver : l’Onthologie. Ce composant sera tout simplement là pour faciliter la communication entre les personnes travaillant dans le même domaine concerné, et sur le même projet.
Quelques outils pour mieux intégrer un algorithme
Parce qu’on n’est jamais assez bien équipé
Après ces explications en douceur des composants d’un algorithme, voici une liste non exhaustive d’outils existants pour les intégrer dans vos projets :
Lucene, qui est une librairie Java, faite par Apache.
L’outil existe depuis à peu près 20 ans, il en est à sa version 9.3. Il permet d’exploiter les composants présentés précédemment, de faire du filtering, du ranking, et du searching dans l’index. Il va également extraire les données des documents que vous allez lui fournir.
Solr, basé sur Lucene.
Les deux serveurs de recherche ont cependant leurs propres bases de données. Solr permet aux utilisateurs de retrouver rapidement des informations dans un grand nombre de documents. En général, le serveur est utilisé pour ses fonctionnalités avancées telles que la recherche plein texte, la recherche par facettes et la génération de suggestions de recherche.
Elasticsearch, basé sur Lucene également.
Ce serveur, bien que très similaire à Solr, est conçu pour être facile à utiliser et à mettre en œuvre, ce qui en fait une option populaire pour les développeurs qui cherchent à ajouter des fonctionnalités de recherche à leurs applications.
MongoDB Atlas, toujours basé sur Lucene.
Cet outil offre des fonctionnalités telles que la réplication de données, la sauvegarde et la restauration, ainsi que la gestion des performances.
Un petit récap ?
Entre définitions, types de recherche, vocabulaire, et méthodologie, comprendre les différentes mécaniques des algorithmes des moteurs de recherche n’est pas une mince affaire.
Le plus important à retenir dans cette histoire, c’est que tout s’imbrique au fur et à mesure. Et peu importe votre requête, les moteurs de recherche mettent tout en œuvre pour que vous parveniez à vos fins, et arriver à l’algorithme de vos rêves.
N’hésitez pas à nous contacter pour en savoir plus sur les algorithmes des moteurs de recherche, nous nous ferons un plaisir d’échanger avec vous et de vous assister !

